

Overview
The Cloud Natural Language API lets you extract entities from text, perform sentiment and syntactic analysis, and classify text into categories. In this lab, we’ll focus on text classification. Using a database of 700+ categories, this API feature makes it easy to classify a large dataset of text.
What you’ll learn
-
Creating a Natural Language API request and calling the API with curl
-
Using the NL API’s text classification feature
-
Using text classification to understand a dataset of news articles
Create an API Key
Since you’ll be using curl to send a request to the Vision API, you’ll need to generate an API key to pass in your request URL. To create an API key, navigate to:
APIs & services > Credentials:
Then click Create credentials:
In the drop down menu, select API key:
Next, copy the key you just generated. Click Close.
Now that you have an API key, save it to an environment variable to avoid having to insert the value of your API key in each request. You can do this in Cloud Shell. Be sure to replace
1
export API_KEY=<YOUR_API_KEY>
Classify a news article
Using the Natural Language API’s classifyText method, you can sort text data into categories with a single API call. This method returns a list of content categories that apply to a text document. These categories range in specificity, from broad categories like /Computers & Electronics to highly specific categories such as /Computers & Electronics/Programming/Java (Programming Language). A full list of 700+ possible categories can be found here.
We’ll start by classifying a single article, and then we’ll see how we can use this method to make sense of a large news corpus. To start, let’s take this headline and description from a New York Times article in the food section:
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.
In your Cloud Shell environment, create a request.json file with the code below. You can either create the file using one of your preferred command line editors (nano, vim, emacs) or use the Cloud Shell code editor:
Create a new file named request.json and add the following:
1
2
3
4
5
6
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}
Now you can send this text to the Natural Language API’s classifyText method with the following curl command:
1
2
curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Look at the response:
1
2
3
4
5
6
7
8
9
10
11
12
{ categories:
[
{
name: '/Food & Drink/Cooking & Recipes',
confidence: 0.85
},
{
name: '/Food & Drink/Food/Meat & Seafood',
confidence: 0.63
}
]
}
The API returned 2 categories for this text:
- /Food & Drink/Cooking & Recipes
- /Food & Drink/Food/Meat & Seafood
The text doesn’t explicitly mention that this is a recipe or even that it includes seafood, but the API is able to categorize it. Classifying a single article is cool, but to really see the power of this feature, let’s classify lots of text data.
Classifying a large text dataset
To see how the classifyText method can help us understand a dataset with lots of text, you’ll use this public dataset of BBC news articles. The dataset consists of 2,225 articles in five topic areas (business, entertainment, politics, sports, tech) from 2004 - 2005. A subset of these articles are in a public Google Cloud Storage bucket. Each of the articles is in a .txt file.
To examine the data and send it to the Natural Language API, you’ll write a Python script to read each text file from Cloud Storage, send it to the classifyText endpoint, and store the results in a BigQuery table. BigQuery is Google Cloud’s big data warehouse tool - it lets you easily store and analyze large data sets.
To see the type of text you’ll be working with, run the following command to view one article (gsutil provides a command line interface for Cloud Storage):
1
gsutil cat gs://text-classification-codelab/bbc_dataset/entertainment/001.txt
Next you’ll create a BigQuery table for your data.
Creating a BigQuery table for our categorized text data
Before sending the text to the Natural Language API, you need a place to store the text and category for each article.
Navigate to the BigQuery in the Console.
Then click on the name of your project, then Create dataset:
Name the dataset: news_classification_dataset
Click Create dataset.
Click on the name of the dataset, then select Create new table. Use the following settings for the new table:
- Create From: empty table
- Name your table article_data
- Click Add Field and add the following 3 fields: article_text, category, and confidence.
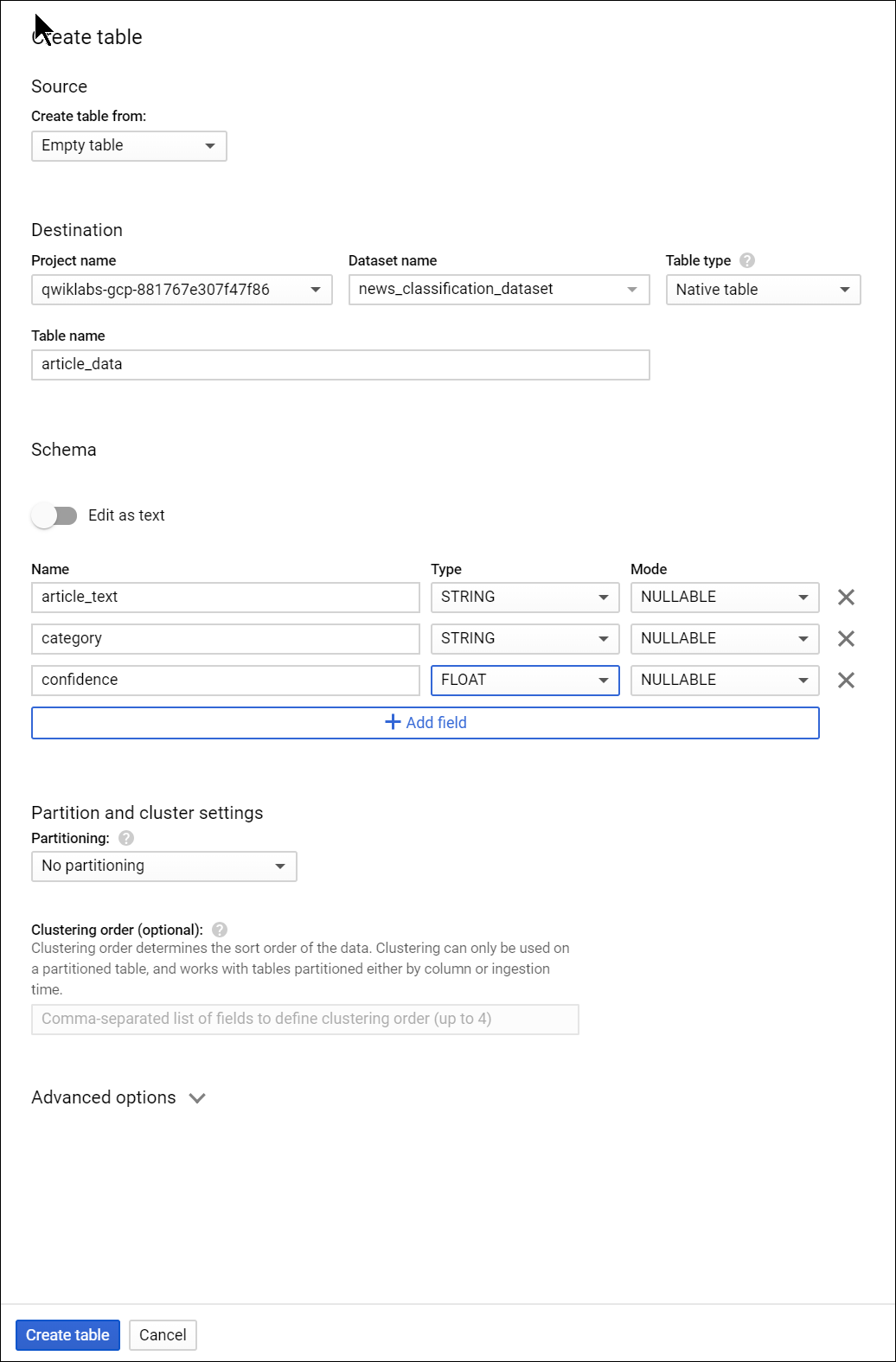
Click Create Table.
The table is empty right now. In the next step you’ll read the articles from Cloud Storage, send them to the Natural Language API for classification, and store the result in BigQuery.
Classifying news data and storing the result in BigQuery
Before writing a script to send the news data to the Natural Language API, you need to create a service account. This will be used to authenticate to the Natural Language API and BigQuery from a Python script.
First, back in Cloud Shell, export the name of your Cloud project as an environment variable. Replace <your_project_name> with the GCP Project ID found in the CONNECTION DETAILS section of the lab:
1
export PROJECT=<your_project_name>
Then run the following commands from Cloud Shell to create a service account:
1
2
3
4
gcloud iam service-accounts create my-account --display-name my-account
gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin
gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=key.json
Now you’re ready to send the text data to the Natural Language API!
To do that, write a Python script using the Python module for Google Cloud. You can accomplish the same thing from any language, there are many different cloud client libraries.
Create a file called classify-text.py and copy the following into it. Replace YOUR_PROJECT with your GCP Project ID.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project id below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_classification_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('text-classification-codelab').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((article_text, nl_response.categories[0].name, nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.insert_rows(table, rows_for_bq)
assert errors == []
Now you’re ready to start classifying articles and importing them to BigQuery. Run the following script:
1
python classify-text.py
The script takes about two minutes to complete, so while it’s running let’s discuss what’s happening.
We’re using the google-cloud Python client library to access Cloud Storage, the Natural Language API, and BigQuery. First, a client is created for each service; then references are created to the BigQuery table. files is a reference to each of the BBC dataset files in the public bucket. We iterate through these files, download the articles as strings, and send each one to the Natural Language API in our classify_text function. For all articles where the Natural Language API returns a category, the article and its category data are saved to a rows_for_bq list. When classifying each article is done, the data is inserted into BigQuery using insert_rows().
Note: The Natural Language API can return more than one category for a document, but for this lab you’re only storing the first category returned to keep things simple.
When the script has finished running, it’s time to verify that the article data was saved to BigQuery.
In BigQuery, navigate to the article_data table in the BigQuery tab and click Query Table:
Edit the results in the Unsaved query box, adding an asterisk between SELECT and FROM:
1
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
Now click Run.
You will see your data when the query completes. Scroll to the right to see the category column.
The category column has the name of the first category the Natural Language API returned for the article, and confidence is a value between 0 and 1 indicating how confident the API is that it categorized the article correctly. You’ll learn how to perform more complex queries on the data in the next step.
Analyzing categorized news data in BigQuery
First, see which categories were most common in the dataset.
In the BigQuery console, click Compose New Query.
Enter the following query, replacing YOUR_PROJECT with your project name:
1
2
3
4
5
6
7
8
9
SELECT
category,
COUNT(*) c
FROM
`YOUR_PROJECT.news_classification_dataset.article_data`
GROUP BY
category
ORDER BY
c DESC
Now click Run.
You should see something like this in the query results:
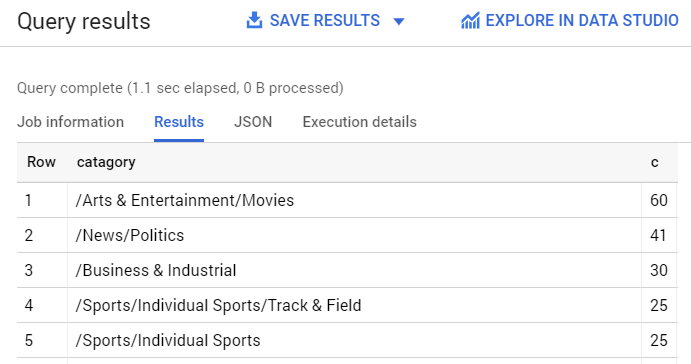
If you wanted to find the article returned for a more obscure category like /Arts & Entertainment/Music & Audio/Classical Music, you could write the following query:
1
2
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
Or, you could get only the articles where the Natural language API returned a confidence score greater than 90%:
1
2
3
4
5
SELECT
article_text,
category
FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE cast(confidence as float64) > 0.9
To perform more queries on your data, explore the BigQuery documentation. BigQuery also integrates with a number of visualization tools. To create visualizations of your categorized news data, check out the Data Studio quickstart for BigQuery.
Congratulations!
You’ve learned how to use the Natural Language API text classification method to classify news articles. You started by classifying one article, and then learned how to classify and analyze a large news dataset using the NL API with BigQuery.
What we’ve covered:
- Creating a Natural Language API classifyText request and calling the API with curl
- Using the Google Cloud Python module to analyze a large news dataset
- Importing and analyzing data in BigQuery
 Never miss a story from us, subscribe to our newsletter
Never miss a story from us, subscribe to our newsletter